Using Google trends is a trend in itself. In a recently published article, Ginsberg et al (2009) develop a simple model forecasting physician visits due to influenza-like illness using only the related query fraction on total queries as recorded by the Google search engine data, available weekly with a short delay.
Following the popularity of the internet as a means for searching for jobs (Stevenson, 2008), this approach has recently been extended to unemployment forecasting. In particular, the Google Index – the incidence of Google job-search related queries over total queries – proved to have predictive power in forecasting unemployment in Germany and Israel (see Askitas and Zimmermann 2009 and Suhoy 2009). Choi and Varian (2009) use the Google Index to predict the initial unemployment claims in the US.
New insights in predicting unemployment in the US
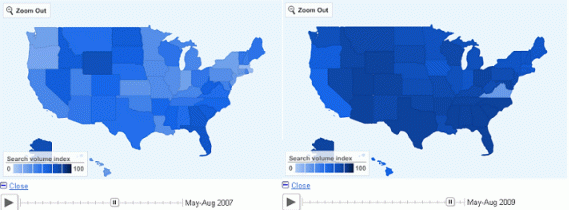
The impact of the crisis on internet job-search activities is clear in Figure 1. This shows the development of the index for the US before and after the onset of the current economic crisis. In two articles focussing on the US (D’Amuri and Marcucci, 2009) and Italy (D’Amuri, 2009), we show that the precision of unemployment forecasts is dramatically improved when the Google job search index is used as a leading indicator.
Figure 1 The evolution of the Google job search index before and during the crisis
Note: the evolution of the Google job search index before (picture on the left, May-Aug 2007) and during the economic crisis (picture on the right, May-Aug 2009). Darker Blue indicates a higher value of the index. Images obtained from this website. See D’Amuri and Marcucci (2009) for details.
We find that models including this index among the explanatory variables outperform more than 300 alternative popular time-series specifications (both linear and non linear) when forecasting at one, two and three steps ahead.
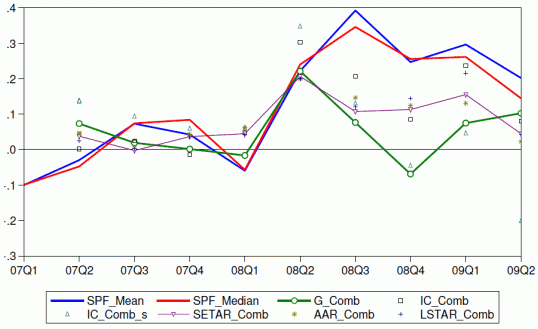
The indicator has power not only at the federal but also at the state level. For 70% of the individual states, the most accurate model includes the Google Index. Models augmented with this Index also outperform the estimates released in the Survey of Professional Forecasters conducted by the Federal Reserve of Philadelphia, having a Mean Squared Error– or forecast measurement error – lower by an order of magnitude (see Figure 2).
Figure 2 Forecast errors, different models versus SPF forecasts
Note: In this table we compare the Survey of Professional Forecasters (SPF) one-quarter-ahead unemployment forecasts with similar forecasts generated from our best models for . The out-of-sample period is 2007.2-2009.6. SPFbest is the best individual forecaster in the survey, SPFmean is the mean of the forecasts, while SPFmedian is the median. Models xComb compute the quarterly forecast as the average of the realised unemployment rate for the first month and the 1- and 2-month-ahead forecasts generated at the end of the first month of the reference quarter. The model with Google (G) is the best model overall, the model with the Initial Claims (IC) is the best model without Google, while the model with subscript ICs is the best model without Google in the short sample. SETAR, LSTAR and AAR are the corresponding non-linear models estimated over the full sample up to the second lag. See D’Amuri and Marcucci (2009) for details.
The predictive power of the index is also confirmed for Italy – the best model that includes the Google Index far outperforms models without it. This finding could be important for policy making since Google data are available almost in real time, while official quarterly unemployment rates are released with approximately two months delay. The potential gains associated with the use of the index are thus even greater in Italy than in the US.
Conclusion
The main limitation of the explanatory variable based on Google data is that it could be partly driven by on-the-job search, rather than unemployed job search activities which are the focus of this paper. Another limitation is due to the fact that not all workers have access to the internet, and it is also presumable that workers using the internet for a job search are not randomly selected among job-seekers. This should be a minor issue, given the increasing popularity of internet as a job search method and also due to the fact that a bias in the estimates would emerge only if shocks hit the unemployed using the internet for job search in a different way.
The intense public interest in unemployment calls for timely and accurate predictions. Our results show that considering Google data is one way to help achieve this.
References
Askitas, Nikoa and Klaus F Zimmermann (2009), “Google Econometrics and Unemployment Forecasting.” IZA Discussion Paper (4201).
Choi, Hyonyoung and Hal Varian (2009), “Predicting Initial Claims for Unemployment Benefits.” Google technical report.
D’Amuri Francesco (2009), “Predicting unemployment in short samples with internet job search query data.” MPRA WP 18403.
D’Amuri, Francesco and Juri Marcucci (2009), ““Google it!” Forecasting the US unemployment rate with a Google job search index.” ISER WP 2009-32.
Ginsberg, Jeremy, Mathew H Mohebbi, Rajan S Patel, Lynnette Brammer, Mark S Smolinski and Larry Brilliant (2009), “Detecting Influenza epidemics using Search Engine Query Data.” Nature (457), pp.1012-1014.
Stevenson, Betsy (2008). “The Internet and Job Search.” NBER Working Paper (13886).
Suhoy, Tanya (2009), “Query Indices and a 2008 Downturn.” Bank of Israel Discussion Paper (06).